|
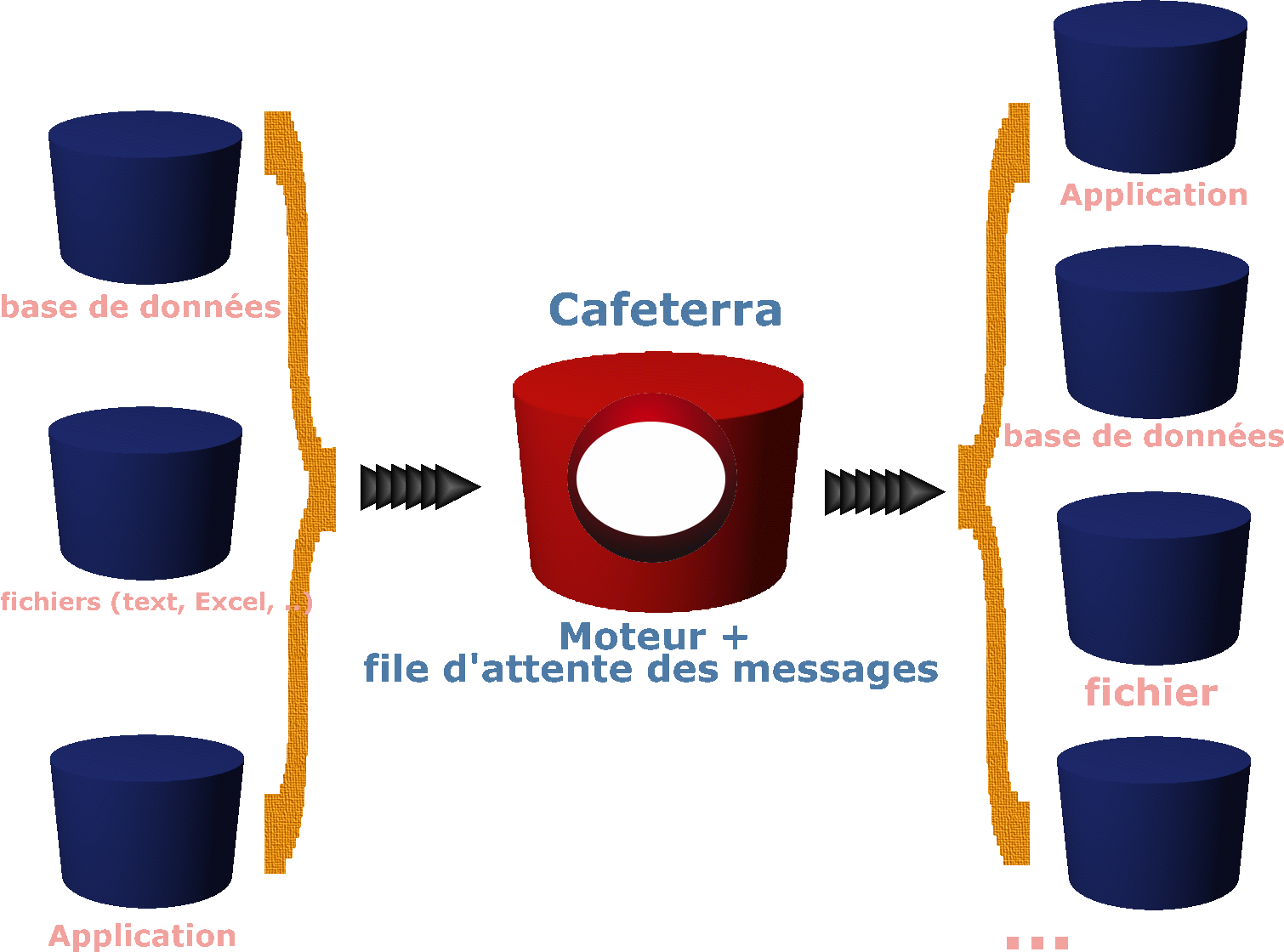
En production, le moteur
récupères les données des application sources (Bases de
données, fichier plat - CSV, Enregistrements de taille fixe,
XML, HPRIM, Excel, etc ...). Ensuite
il effectue les transformation prédéfini dans le flux. En
dernière étape, cafeterra délivre un nouveau message
transformé aux application destinatrices. Eventuellement,
si vous le préciser dans la définition du flux, Cafeterra
stocke dans la base de données Postgres, le message entrant
ainsi que les différents messages sortants. Les
messages entrant peuvent être:
- simple et monosources.
-complexe et provenant de plusieurs sources. |